Is data the oil of the 21rst century? Such and similar questions are often asked these days.1 Especially in Germany and the EU public policy encourages and requests increased usage of new and reuse of existing data. We are a small company with a strong focus on research data management2 and want to give an insight into the status quo and future of research data management.
Status Quo Research Data Management 2022
The IT departments of many universities in Germany often follow their own scattered and incoherent approaches. Legacy systems with old and outdated software, a lack of personnel, unconnected data structures conflict with rising expectations for how to use existing data and the growing amounts of new data. At many institutes, workarounds have become standard practice! Scientists transport data via USB stick routinely, copy data columns manually from Excel, have to deal with scientific devices with insufficiently connect with data platforms and so on. Even paper based workflows are still commonplace, for example for lab notebooks. Universities use different standards, which makes collaboration difficult and slows it down.
Just as the triumph of information technologies is accompanied by growing pains of various kinds in society, the build-up of IT infrastructure in science has room for improvement. Overcoming the existing workaround solutions may take years of decades, but the software standards are developed today. Today’s solutions are diverse: Software with different licensing, especially closed and open source, created by different groups from small to whole institutes and with the need to interact with each other.
The FAIR principles
FAIR means Findable, Accessible, Interoperable and Reusable. There is a worldwide push that future research data management systems enable scientists to follow these principles. 3
Research data is an untapped treasure
Elevating research standards to a common standard is one of the biggest tasks at the moment. Scientists of the past and the future are united in their trust that the next generations can build on their work. The value of data that long-dead people created is obvious, for example in the context of historical weather data with regard to climate change research. But a lot of valuable historical data is hard to use. Old formats or event paper demands quite an effort to make them available. The task of research data management is to make data acquisition forward thinking. All data that users create today should be continually reusable in the future. There is a gap to close with hard to access historical data. How and where this historical data exists is often clear. Finding the time and capacity to digitize them is usually harder. Systems with open interfaces and software that are easy to adjust are future-ready by default. Using these systems, data can be moved into new and open formats in a flexible manner. This makes exploiting the data treasure more easy in the future.
In our Structured-Data-Workshop you can learn from our RDM (research data management) experts how the untapped treasure can get into your data set and how to prepare future data optimally for further usage.
What should future research data management look like?
Creating knowledge according to the aforementioned FAIR principles would ideally look like this: All parts of the process are based on open source software. There are open programming interfaces, that allow to integrate new procedures and data easily. The researchers have an easy and intuitive interface, and for the majority do not need to care about the use of the backend. They can focus on scientific work. The research data is managed automatically in the background. Data sets are archived automatically, access to them are adjusted technically with rights management controls.
The result: Raw data, analysis based on it and analysis based on the analysis etc up until publication are connected to each other in a transparent manner (also see this example). Working like this with open standards will make collaboration easier and allows to reproduce how data was created and used. To preserve this research data for the future optimally, it must be saved in the research data management software in its original context. This allows recovering the origin of data (see: reproducibility crisis) and to use research data again for further discoveries.
The used software should be open source and therefore future-proof. Due to the open source nature of the software it is the decision of the users, how and by whom the software is maintained and improved. The users can develop the software partly by themselves. Proprietary specialty software for distinct use cases should be documented and archived religiously. Ideally these proprietary software parts are changed to open standards in the future. Otherwise there is the risk that this software could be difficult to work with in a few years. If the development of a software project is discontinued although it is used in production, there will always be problems. As opposed to closed source software, for free software the decision whether to continue a project or not does not depend on the financial interests of one company.
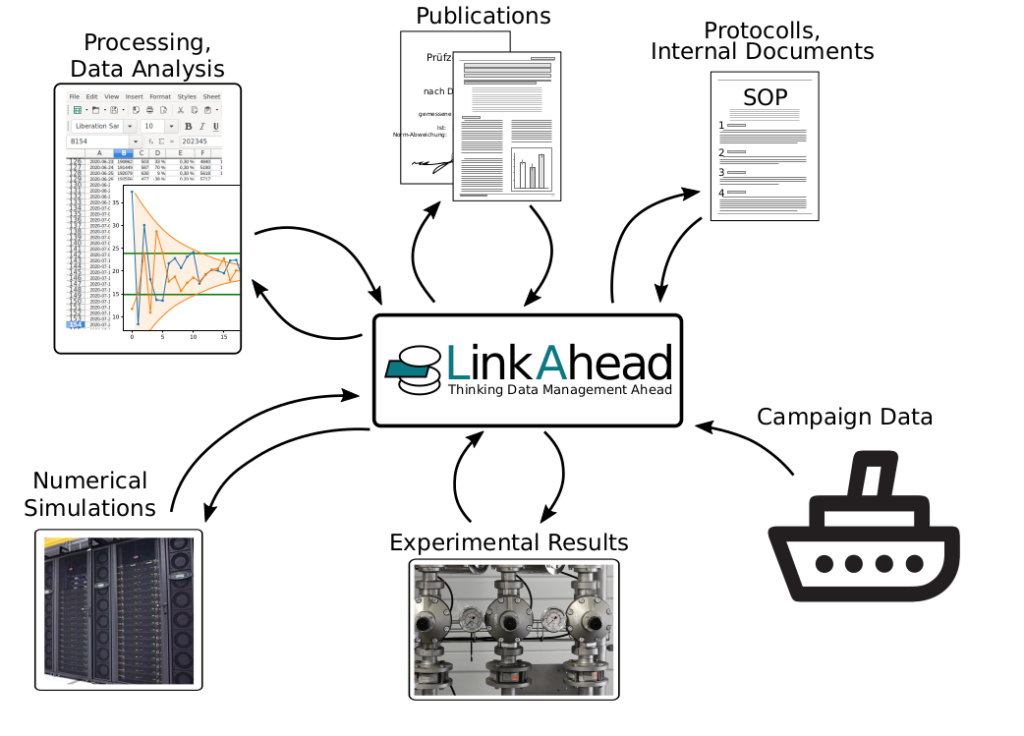
IndiScale and LinkAhead
Using the potential in research data management is the mission that the team at IndiScale has been working on since 2012 (first as scientists at the Max Planck Institute for Dynamics and Self-Organization, from 2019 on at IndiScale), and LinkAhead ist the solution. We want to shape and influence the path that research data management software takes. We see ourselves as a part of the open source movement. With the help of open standards and licenses we help users regain control over the software that they use every day. Software should be under the control of its users, therefore the code should be publicly available and the access and licensing must be open so that there is no mandatory dependence on companies. Also software should be as free as science: Openly available and accessible for everyone. That’s why we develop the open source research data management software CaosDB, a tool that we dearly missed during our own studies. For professional use by our customers, the CaosDB distribution LinkAhead is available and has commercial support.
1 https://www.deutschlandfunkkultur.de/malte-spitz-daten-das-oel-des-21-jahrhunderts-ueber-die-100.html
2 https://www.indiscale.com/our-services/
3 https://www.go-fair.org/go-fair-initiative/go-fair-offices/